pickle - Serializzazione di oggetti
Scopo: Serializzazione di oggetti
Il modulo pickle implementa un algoritmo per trasformare un oggetto arbitrario Python in un una serie di byte. Questo processo viene anche detto serializzazione dell'oggetto). Il flusso di byte che rappresenta l'oggetto può essere trasmesso o conservato, e successivamente ricostruito per creare un nuovo oggetto con le stesse caratteristiche (deserializzazione) .
Codificare e Decodificare Dati in Stringhe
Il primo esempio usa dumps() per codificare una struttura dati come stringa, quindi stampa la stringa verso la console. Usa una struttura dati composta internamente di tipi built-in. Le istanze di qualsiasi classe possono essere serializzate con pickle, come verrà in seguito illustrato con un esempio.
# pickle_string.py
import pickle
import pprint
data = [{'a': 'A', 'b': 2, 'c': 3.0}]
print('DATI:', end=' ')
pprint.pprint(data)
data_string = pickle.dumps(data)
print('PICKLE: {!r}'.format(data_string))
In modalità predefinita, i dati verrano scritti nel formato binario maggiormente compatibile quando occorre condividerli tra programmi Python 3.
$ python3 pickle_string.py
DATI: [{'a': 'A', 'b': 2, 'c': 3.0}]
PICKLE: b'\x80\x04\x95#\x00\x00\x00\x00\x00\x00\x00]\x94}\x94(\x8c\x01a\x94\x8c\x01A\x94\x8c\x01b\x94K\x02\x8c\x01c\x94G@\x08\x00\x00\x00\x00\x00\x00ua.'
Una volta che i datai sono serializzati, possono essere scritti in un file, socket , pipe ecc. Successivamente si può leggere il file e recuperare i dati per costruire un nuovo oggetto con gli stessi valori.
# pickle_unpickle.py
import pickle
import pprint
data1 = [{'a': 'A', 'b': 2, 'c': 3.0}]
print('PRIMA : ', end=' ')
pprint.pprint(data1)
data1_string = pickle.dumps(data1)
data2 = pickle.loads(data1_string)
print('DOPO : ', end=' ')
pprint.pprint(data2)
print('STESSI?:', (data1 is data2))
print('UGUALI?:', (data1 == data2))
il nuovo oggetto costruito è uguale ma non è lo stesso oggetto originale.
$ python3 pickle_unpickle.py
PRIMA : [{'a': 'A', 'b': 2, 'c': 3.0}]
DOPO : [{'a': 'A', 'b': 2, 'c': 3.0}]
STESSI?: False
UGUALI?: True
Lavorare con Flussi
Oltre a dumps() e loads(), pickle fornisce un paio di funzioni di convenienza per lavorare con flussi tipo file. E' possibile scrivere oggetti multipli verso un flusso, quindi leggerli da esso senza sapere in anticipo quanti oggetti sono stati scritti o quanto grandi essi siano.
# pickle_stream.py
import io
import pickle
import pprint
class SimpleObject:
def __init__(self, name):
self.name = name
self.name_backwards = name[::-1]
return
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('preserva'))
data.append(SimpleObject('ultimo'))
# Simula a file.
out_s = io.BytesIO()
# Scrive verso lo stream
for o in data:
print('IN SCRITTURA : {} ({})'.format(o.name, o.name_backwards))
pickle.dump(o, out_s)
out_s.flush()
# Imposta uno stream leggibile
in_s = io.BytesIO(out_s.getvalue())
# Legge i dati
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print('LETTURA : {} ({})'.format(
o.name, o.name_backwards))
L'esempio simula dei flussi usando due buffer BytesIO. Il primo riceve gli oggetti serializzati e il suo valore viene passato al secondo dal quale legge load(). Anche un semplice formato di database potrebbe usare questo sistema per conservare i dati. Il modulo shelve rappresenta questo tipo di implementazione.
$ python3 pickle_stream.py IN SCRITTURA : pickle (elkcip) IN SCRITTURA : preserva (avreserp) IN SCRITTURA : ultimo (omitlu) LETTURA : pickle (elkcip) LETTURA : preserva (avreserp) LETTURA : ultimo (omitlu)
Oltre alla conservazione di dati, gli oggetti serializzati con pickle sono molto comodi per comunicazioni tra processi. Ad esempio usando os.fork() ed os.pipe() si possono stabilire degli elaboratori di richieste che leggono delle istruzioni da elaborare da una pipe e scrivono i risultati in un'altra pipe. Il codice base per la gestione del gruppo di elaboratori di richieste e per l'invio delle istruzioni e la ricezione delle risposte può essere riusato, visto che gli oggetti delle istruzioni e risposta non devono essere di una classe particolare. Se si stanno usando pipe o socket, non ci si deve dimenticare di eseguire uno svuotamento dopo avere disposto ogni oggetto, per spingere i dati attraverso la connessione verso l'altro estremo. Si veda il modulo multiprocessing se non si vuole scrivere il proprio gestore del gruppo di elaboratori di richieste.
Problemi nella Ricostruzione degli Oggetti
Quando si lavora con le proprie classi, ci si deve assicurare che la classe che si vuole serializzare appaia nello spazio dei nomi del processo che sta leggendo il pickle. Solo i dati per quell'istanza vengono trattati, non la definizione della classe. Il nome della classe viene usato per trovare il costruttore per creare il nuovo oggetto quando viene deserializzato. L'esempio seguente scrive delle istanze di una classe verso un file.
# pickle_dump_to_file_1.py
import pickle
import sys
class SimpleObject:
def __init__(self, name):
self.name = name
l = list(name)
l.reverse()
self.name_backwards = ''.join(l)
if __name__ == '__main__':
data = []
data.append(SimpleObject('pickle'))
data.append(SimpleObject('preserva'))
data.append(SimpleObject('ultimko'))
filename = sys.argv[1]
with open(filename, 'wb') as out_s:
for o in data:
print('IN SCRITTURA: {} ({})'.format(
o.name, o.name_backwards))
pickle.dump(o, out_s)
Quando viene eseguito, lo script crea un file il cui nome ò quello passato come argomento da riga di comando.
$ python3 pickle_load_from_file_1.py test.dat
Traceback (most recent call last):
File "pickle_load_from_file_1.py", line 12, in <module>
o = pickle.load(in_s)
AttributeError: Can't get attribute 'SimpleObject' on <module '__main__' from 'pickle_load_from_file_1.py'>
Un tentativo semplicistico di caricare gli oggetti serializzati risultanti fallirebbe.
# pickle_load_from_file_1.py
import pickle
import pprint
import sys
filename = sys.argv[1]
with open(filename, 'rb') as in_s:
while True:
try:
o = pickle.load(in_s)
except EOFError:
break
else:
print('LETTI: {} ({})'.format(
o.name, o.name_backwards))
Questa versione fallisce perchò non ò disponibile alcuna classe SimpleObject.
$ python3 pickle_load_from_file_1.py test.dat
Traceback (most recent call last):
File "pickle_load_from_file_1.py", line 12, in <module>
o = pickle.load(in_s)
AttributeError: Can't get attribute 'SimpleObject' on <module '__main__' from 'pickle_load_from_file_1.py'>
La versione corretta, che importa SimpleObject dallo script originale, ha successo. L'aggiunta dell'istruzione di importazione alla file dell'elenco delle risorse importate consente allo script di trovare la classe e costruire l'oggetto.
from pickle_dump_to_file_1 import SimpleObject
L'esecuzione dello script modificato ora produce il risultato atteso.
$ python3 pickle_dump_to_file_2.py test.dat
File "pickle_dump_to_file_2.py", line 29
print 'LETTURA: %s (%s)' % (o.name, o.name_backwards)
^
SyntaxError: invalid syntax
Oggetti non Serializzabili
Non tutti gli oggetti possono essere serializzati da pickle socket, handle di file, connessioni a database e altri oggetti con uno stato a livello di esecuzione che dipende dal sistema operativo o da un altro processo potrebbero essere impossibili da salvare in un modo efficace. Gli oggetti che hanno attributi che non possono essere elaborati da pickle possono definire __getstate__() e __setstate__() per restituire un sottoinsieme dello stato dell'istanza da serializzare.
Il metodo __getstate__() deve ritornare un oggetto che contenga lo stato interno dell'oggetto. Un comodo metodo per rappresentare questo stato è con un dizionario, ma il valore può essere un qualunque oggetto che possa essere serializzato. Lo stato viene conservato, quindi passato a __setstate()__ quando l'oggetto viene caricato per la deserializzazione.
# pickle_state.py
import pickle
class State:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'State({!r})'.format(self.__dict__)
class MyClass:
def __init__(self, name):
print('MyClass.__init__({})'.format(name))
self._set_name(name)
def _set_name(self, name):
self.name = name
self.computed = name[::-1]
def __repr__(self):
return 'MyClass({!r}) (calcolato={!r})'.format(
self.name, self.computed)
def __getstate__(self):
state = State(self.name)
print('__getstate__ -> {!r}'.format(state))
return state
def __setstate__(self, state):
print('__setstate__({!r})'.format(state))
self._set_name(state.name)
inst = MyClass('qui il nome')
print('Prima:', inst)
dumped = pickle.dumps(inst)
reloaded = pickle.loads(dumped)
print('Dopo :', reloaded)
Questo esempio usa un oggetto State separato per mantenere lo stato interno di MyClass. Quando un'istanza di MyClass viene caricata da un elemento serializzato da pickle, __setstate__() viene passato all'istanza di State che lo usa per inizializzare l'oggetto.
$ python3 pickle_state.py
MyClass.__init__(qui il nome)
Prima: MyClass('qui il nome') (calcolato='emon li iuq')
__getstate__ -> State({'name': 'qui il nome'})
__setstate__(State({'name': 'qui il nome'}))
Dopo : MyClass('qui il nome') (calcolato='emon li iuq')
False, __setstate__() non viene chiamato quando l'oggetto viene deserializzato.Riferimenti Circolari
Il protocollo di pickle gestisce automaticamente i riferimenti circolari tra gli oggetti, quindi non ci si deve preoccupare di fare qualcosa di speciale con complesse strutture di dati. Si consideri il digrafo seguente. Include parecchi cicli, tuttavia la struttura corretta può essere serializzata, quindi deserializzata.
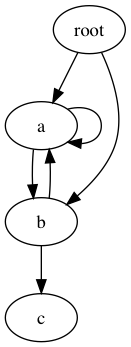
Sebbene il grafico includa diversi cicli, la struttura corretta può essere serializzata e successivamente ricaricata.
# pickle_cycle.py
import pickle
class Node:
"""Un semplice digrafo
"""
def __init__(self, name):
self.name = name
self.connections = []
def add_edge(self, node):
"Crea un collegamento tra questo nodo e gli altri."
self.connections.append(node)
def __iter__(self):
return iter(self.connections)
def preorder_traversal(root, seen=None, parent=None):
"""Generatore che fornisce i collegamenti in un grafo.
"""
if seen is None:
seen = set()
yield (parent, root)
if root in seen:
return
seen.add(root)
for node in root:
recurse = preorder_traversal(node, seen, root)
for parent, subnode in recurse:
yield (parent, subnode)
def show_edges(root):
"Stampa tutti i collegamenti nel grafo."
for parent, child in preorder_traversal(root):
if not parent:
continue
print('{:>5} -> {:>2} ({})'.format(
parent.name, child.name, id(child)))
# Imposta i nodi.
root = Node('root')
a = Node('a')
b = Node('b')
c = Node('c')
# Aggiunge i collegamenti tra i nodi.
root.add_edge(a)
root.add_edge(b)
a.add_edge(b)
b.add_edge(a)
b.add_edge(c)
a.add_edge(a)
print('GRAFO ORIGINALE :')
show_edges(root)
# Serializza e deserializza il grafo per creare
# un nuovo insieme di nodi.
dumped = pickle.dumps(root)
reloaded = pickle.loads(dumped)
print('\nGRAFO RICARICATO:')
show_edges(reloaded)
I nodi ricaricati non sono lo stesso oggetto, ma la relazione tra i nodi ò mantenuta e viene ricaricata solo una copia dell'oggetto con riferimenti multipli. Entrambe queste affermazioni possono essere verificate esaminando i valori di id() dei nodi, prima e dopo il passaggio di serializzazione e deserializzazione.
$ python3 pickle_cycle.py
GRAFO ORIGINALE :
root -> a (140450602566416)
a -> b (140450601802720)
b -> a (140450602566416)
b -> c (140450601633584)
a -> a (140450602566416)
root -> b (140450601802720)
GRAFO RICARICATO:
root -> a (140450601127072)
a -> b (140450600563760)
b -> a (140450601127072)
b -> c (140450600565056)
a -> a (140450601127072)
root -> b (140450600563760)
Vedere anche:
- pickle
- La documentazione della libreria standard per questo modulo.
- PEP 3154
- Il protocollo pickle versione 4
- shelve
- Il modulo shelve
- Pickle: An Interesting stack language
- di Alexandre Vassalotti